WGAN-GP(Train Wasserstein GAN with Gradient Penalty)
WGANを改良したWGAN-GPの実装を行います。WGANではクリッピングされた重みが2極化するため勾配消失や勾配爆発が起きやすくなる課題がありました。改良版のWGAN-GPでは、重みのクリッピングではなく、勾配に制約をつける手法が提案されました。
WGAN-GPの特徴
WGAN-GPでは、Dの学習時に生成画像と実画像を一定の割合(Alpha)で混ぜ合わせたものをDに入力した時の出力の勾配が1から離れることに対してペナルティを課します。論文では以下のように記載されています。

勾配ペナルティ損失計算のコードは以下のようになります。(こちらのコードを参照しました)本物画像と偽物画像を一定の割合で混ぜ合わせて計算しています。
# 勾配ペナルティ損失の計算
def compute_gradient_penalty(D, real_samples, fake_samples):
# ランダムな混合割合を取得
alpha = Tensor(np.random.random((real_samples.size(0), 1, 1, 1)))
# 生成画像と実画像を一定の割合(alpha)で混ぜ合わせた画像でDの勾配を取得
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
d_interpolates = D(interpolates)
fake = Variable(Tensor(real_samples.shape[0], 1).fill_(1.0), requires_grad=False)
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
# 勾配ペナルティ損失を計算
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penaltyWGAN-GPの実装
Google Colabで動作するソースはGithubに置いてます。興味のあるかたは試してみてください。



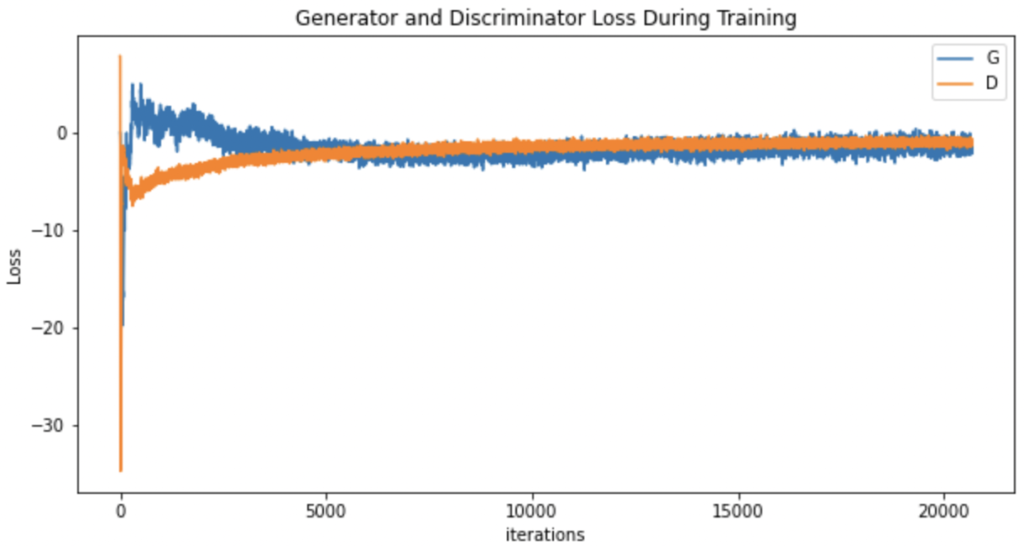
1000回目までなので、まだまだですが、WGANに比べるとノイズも少ない綺麗な画像になっています。損失の推移と生成画像の変化をGIFにまとめてみました。

最後に
WGANと比べると生成の精度も上がっています。アルゴリズムの理解を目的としましたのでMNISTを使っていますが、違うデータセットを使えばもっと生成能力を体感できるはずです。
比較した最初のWGANについてはこちらを参照してください。

WGAN-GPの論文はこちらです。
![[1704.00028] Improved Training of Wasserstein GANs](http://taviko.com/wp-content/uploads/luxe-blogcard/e/e6bcae4e8e4f5a899893ef8fe7a9438f.png)